Domande Frequenti
I miei test sono molto lenti
Quando utilizzi questo @wdio/ocr-service non lo stai usando per velocizzare i tuoi test, lo usi perché hai difficoltà a localizzare elementi nella tua app web/mobile e vuoi un modo più semplice per localizzarli. E tutti speriamo di sapere che quando vuoi qualcosa, perdi qualcos'altro. Ma...., c'è un modo per far eseguire il @wdio/ocr-service più velocemente del normale. Maggiori informazioni su questo possono essere trovate qui.
Posso usare i comandi di questo servizio con i comandi/selettori predefiniti di WebdriverIO?
Sì, puoi combinare i comandi per rendere il tuo script ancora più potente! Il consiglio è di utilizzare i comandi/selettori predefiniti di WebdriverIO il più possibile e utilizzare questo servizio solo quando non riesci a trovare un selettore unico, o il tuo selettore diventerà troppo fragile.
Il mio testo non viene trovato, come è possibile?
Prima di tutto, è importante capire come funziona il processo OCR in questo modulo, quindi leggi questa pagina. Se ancora non riesci a trovare il tuo testo, potresti provare le seguenti cose.
L'area dell'immagine è troppo grande
Quando il modulo deve elaborare un'area ampia dello screenshot potrebbe non trovare il testo. Puoi fornire un'area più piccola fornendo un haystack quando usi un comando. Controlla i comandi per vedere quali comandi supportano la fornitura di un haystack.
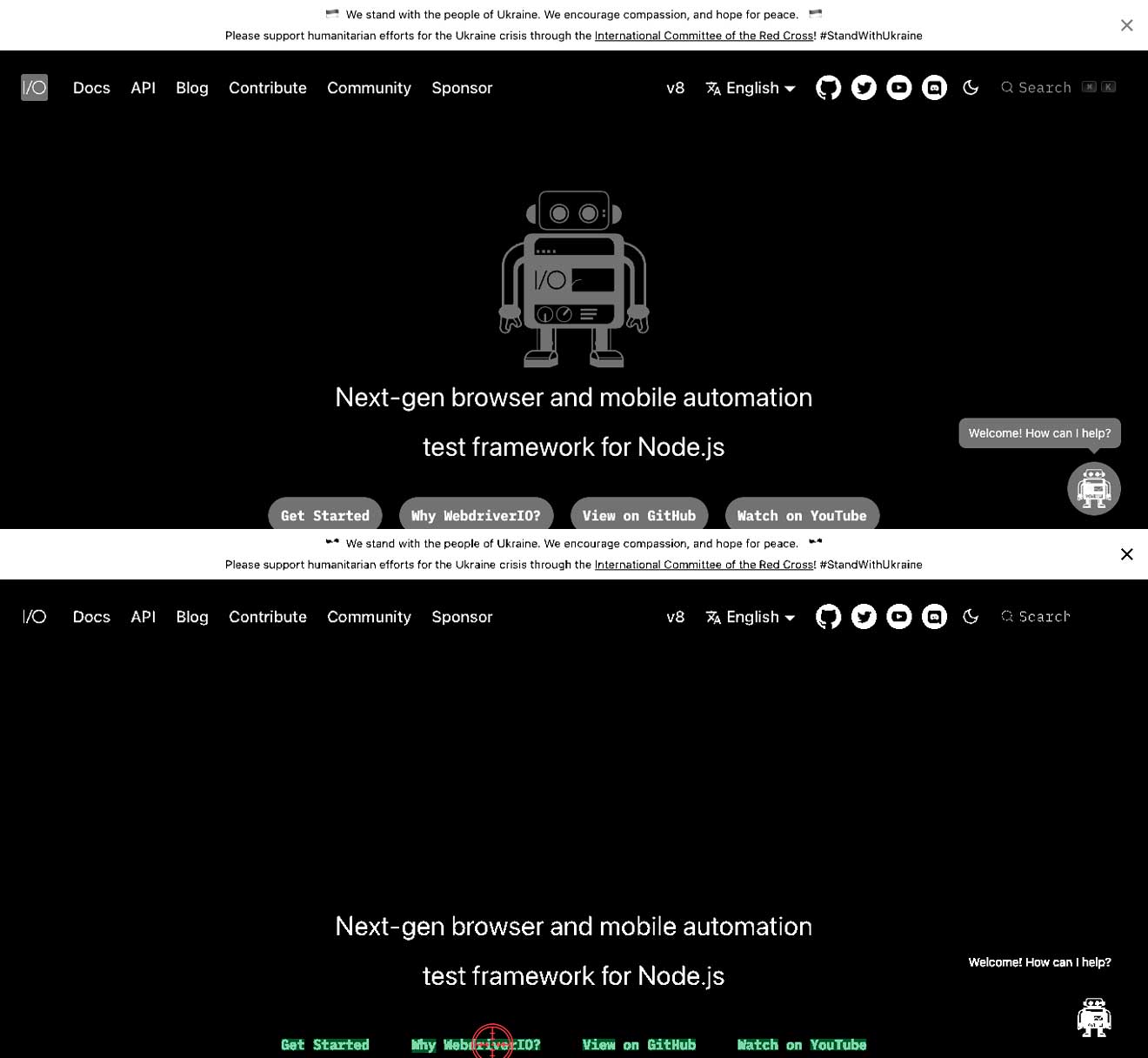
Il contrasto tra il testo e lo sfondo non è corretto
Questo significa che potresti avere testo chiaro su sfondo bianco o testo scuro su sfondo scuro. Questo può risultare nell'impossibilità di trovare il testo. Negli esempi seguenti puoi vedere che il testo Why WebdriverIO? è bianco e circondato da un pulsante grigio. In questo caso, ciò comporterà di non trovare il testo Why WebdriverIO?. Aumentando il contrasto per il comando specifico, trova il testo e può cliccarlo, vedi la seconda immagine.
await driver.ocrClickOnText({
haystack: { height: 44, width: 1108, x: 129, y: 590 },
text: "WebdriverIO?",
// // Con il contrasto predefinito di 0.25, il testo non viene trovato
contrast: 1,
});
Perché il mio elemento viene cliccato ma la tastiera sui miei dispositivi mobili non appare mai?
Questo può accadere su alcuni campi di testo dove il clic è determinato troppo lungo e considerato un tap lungo. Puoi utilizzare l'opzione clickDuration su ocrClickOnText e ocrSetValue per alleviare questo problema. Vedi qui.
Questo modulo può restituire più elementi come normalmente può fare WebdriverIO?
No, attualmente non è possibile. Se il modulo trova più elementi che corrispondono al selettore fornito, troverà automaticamente l'elemento che ha il punteggio di corrispondenza più alto.
Posso automatizzare completamente la mia app con i comandi OCR forniti da questo servizio?
Non l'ho mai fatto, ma in teoria dovrebbe essere possibile. Facci sapere se ci riesci ☺️.
Vedo un file extra chiamato {languageCode}.traineddata che viene aggiunto, cos'è?
{languageCode}.traineddata è un file di dati linguistici utilizzato da Tesseract. Contiene i dati di addestramento per la lingua selezionata, che include le informazioni necessarie affinché Tesseract riconosca efficacemente caratteri e parole in inglese.
Contenuti di {languageCode}.traineddata
Il file generalmente contiene:
- Dati del Set di Caratteri: Informazioni sui caratteri nella lingua inglese.
- Modello Linguistico: Un modello statistico di come i caratteri formano parole e le parole formano frasi.
- Estrattori di Caratteristiche: Dati su come estrarre caratteristiche dalle immagini per il riconoscimento dei caratteri.
- Dati di Addestramento: Dati derivati dall'addestramento di Tesseract su un ampio set di immagini di testo inglese.
Perché {languageCode}.traineddata è importante?
- Riconoscimento Linguistico: Tesseract si basa su questi file di dati addestrati per riconoscere e processare accuratamente il testo in una specifica lingua. Senza
{languageCode}.traineddata, Tesseract non sarebbe in grado di riconoscere il testo inglese. - Prestazioni: La qualità e l'accuratezza dell'OCR sono direttamente correlate alla qualità dei dati di addestramento. L'utilizzo del file di dati addestrato corretto assicura che il processo OCR sia il più accurato possibile.
- Compatibilità: Assicurarsi che il file
{languageCode}.traineddatasia incluso nel tuo progetto rende più facile replicare l'ambiente OCR su diversi sistemi o macchine dei membri del team.
Versionamento di {languageCode}.traineddata
Includere {languageCode}.traineddata nel tuo sistema di controllo versione è consigliato per i seguenti motivi:
- Consistenza: Assicura che tutti i membri del team o gli ambienti di deployment utilizzino esattamente la stessa versione dei dati di addestramento, portando a risultati OCR coerenti in ambienti diversi.
- Riproducibilità: Archiviare questo file nel controllo versione rende più facile riprodurre i risultati quando si esegue il processo OCR in un momento successivo o su una macchina diversa.
- Gestione delle Dipendenze: Includerlo nel sistema di controllo versione aiuta nella gestione delle dipendenze e assicura che qualsiasi setup o configurazione dell'ambiente includa i file necessari per l'esecuzione corretta del progetto.
C'è un modo semplice per vedere quale testo viene trovato sul mio schermo senza eseguire un test?
Sì, puoi utilizzare il nostro wizard CLI per questo. La documentazione può essere trovata qui
