자주 묻는 질문
내 테스트가 매우 느립니다
@wdio/ocr-service를 사용할 때, 이것을 테스트 속도를 높이기 위해 사용하는 것이 아니라 웹/모바일 앱에서 요소를 찾기 어려울 때 더 쉽게 요소를 찾기 위해 사용합니다. 우리 모두 무언가를 얻으면 다른 것을 잃는다는 것을 알고 있습니다. 하지만...., @wdio/ocr-service를 평소보다 더 빠르게 실행하는 방법이 있습니다. 이에 대한 자세한 정보는 여기에서 찾을 수 있습니다.
이 서비스의 명령을 기본 WebdriverIO 명령/선택자와 함께 사용할 수 있나요?
네, 명령을 조합하여 스크립트를 더 강력하게 만들 수 있습니다! 가능한 한 기본 WebdriverIO 명령/선택자를 최대한 사용하고, 고유한 선택자를 찾을 수 없거나 선택자가 너무 취약해질 경우에만 이 서비스를 사용하는 것이 좋습니다.
내 텍스트가 발견되지 않는데, 어떻게 된 것인가요?
먼저, 이 모듈에서 OCR 프로세스가 어떻게 작동하는지 이해하는 것이 중요합니다. 이 페이지를 읽어보세요. 그래도 텍스트를 찾을 수 없다면 다음과 같은 방법을 시도해 볼 수 있습니다.
이미지 영역이 너무 큽니다
모듈이 스크린샷의 큰 영역을 처리해야 할 때 텍스트를 찾지 못할 수 있습니다. 명령을 사용할 때 haystack을 제공하여 더 작은 영역을 지정할 수 있습니다. haystack 제공을 지원하는 명령을 확인하려면 명령을 확인하세요.
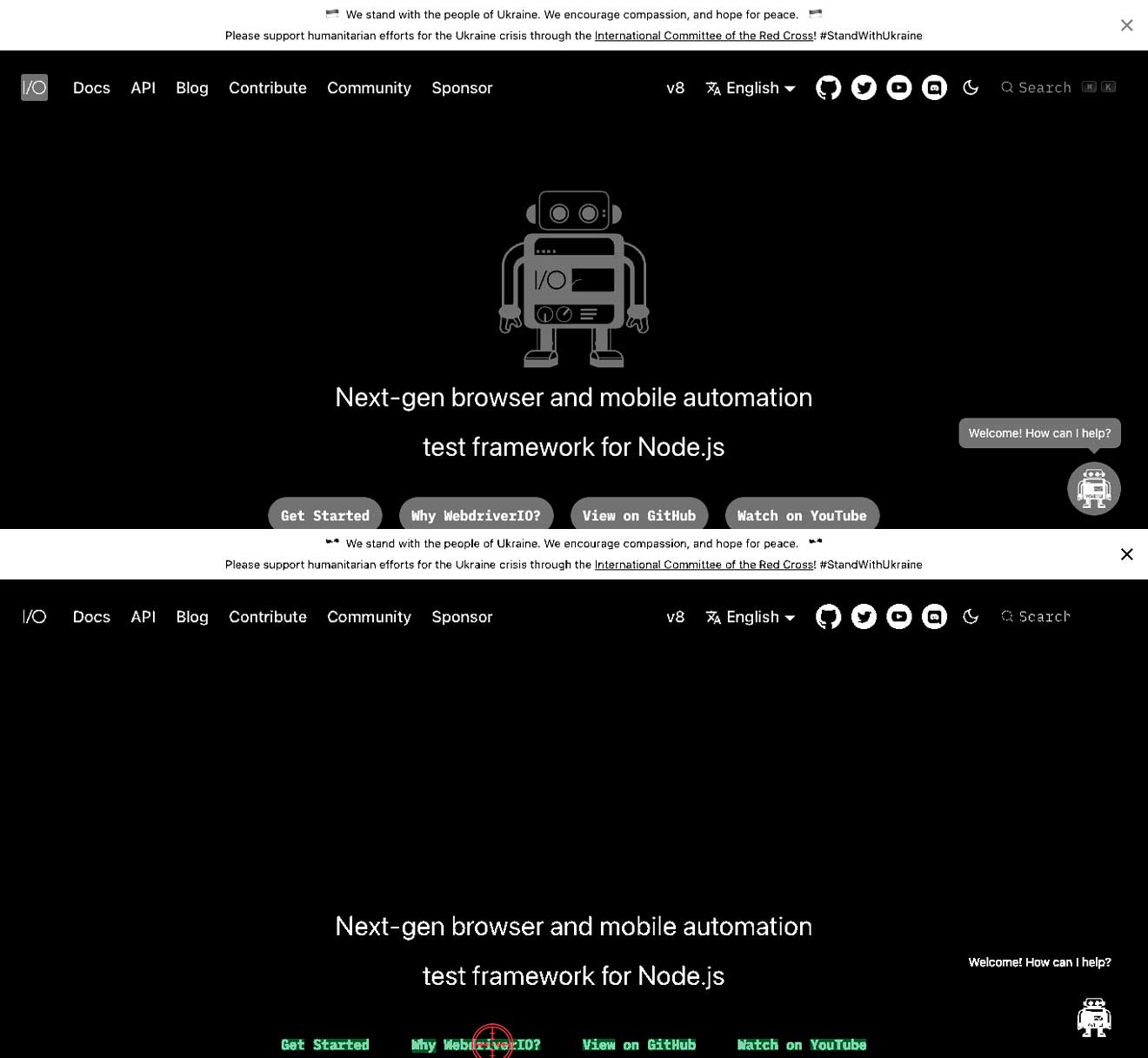
텍스트와 배경 사이의 대비가 올바르지 않습니다
이는 흰색 배경에 밝은 텍스트가 있거나 어두운 배경에 어두운 텍스트가 있을 수 있다는 의미입니다. 이로 인해 텍스트를 찾지 못할 수 있습니다. 아래 예시에서 Why WebdriverIO? 텍스트가 흰색이고 회색 버튼으로 둘러싸여 있는 것을 볼 수 있습니다. 이 경우 Why WebdriverIO? 텍스트를 찾을 수 없습니다. 특정 명령에 대한 대비를 높이면 텍스트를 찾아 클릭할 수 있습니다. 두 번째 이미지를 참조하세요.
await driver.ocrClickOnText({
haystack: { height: 44, width: 1108, x: 129, y: 590 },
text: "WebdriverIO?",
// // 기본 대비 0.25에서는 텍스트가 발견되지 않습니다
contrast: 1,
});
요소가 클릭되는데 모바일 기기에서 키보드가 나타나지 않는 이유는 무엇인가요?
일부 텍스트 필드에서는 클릭이 너무 길게 감지되어 롱탭으로 간주될 수 있습니다. ocrClickOnText와 ocrSetValue에서 clickDuration 옵션을 사용하여 이 문제를 완화할 수 있습니다. 여기를 참조하세요.
이 모듈이 WebdriverIO가 일반적으로 할 수 있는 것처럼 여러 요소를 반환할 수 있나요?
아니요, 현재는 불가능합니다. 모듈이 제공된 선택자와 일치하는 여러 요소를 찾으면 자동으로 일치 점수가 가장 높은 요소를 찾습니다.
이 서비스에서 제공하는 OCR 명령으로 내 앱을 완전히 자동화할 수 있나요?
저는 해본 적이 없지만, 이론적으로는 가능해야 합니다. 성공하셨다면 알려주세요 ☺️.
{languageCode}.traineddata라는 추가 파일이 보이는데, 이게 뭔가요?
{languageCode}.traineddata는 Tesseract에서 사용하는 언어 데이터 파일입니다. 선택한 언어에 대한 훈련 데이터를 포함하고 있으며, Tesseract가 영어 문자와 단어를 효과적으로 인식하는 데 필요한 정보를 담고 있습니다.
{languageCode}.traineddata의 내용
이 파일은 일반적으로 다음을 포함합니다:
- 문자 집합 데이터: 영어 언어의 문자에 대한 정보.
- 언어 모델: 문자가 단어를 형성하고 단어가 문장을 형성하는 방법에 대한 통계적 모델.
- 특징 추출기: 문자 인식을 위해 이미지에서 특징을 추출하는 방법에 대한 데이터.
- 훈련 데이터: 대량의 영어 텍스트 이미지에 대한 Tesseract 훈련에서 파생된 데이터.
{languageCode}.traineddata가 중요한 이유는 무엇인가요?
- 언어 인식: Tesseract는 이러한 훈련된 데이터 파일에 의존하여 특정 언어의 텍스트를 정확하게 인식하고 처리합니다.
{languageCode}.traineddata없이는 Tesseract는 영어 텍스트를 인식할 수 없습니다. - 성능: OCR의 품질과 정확도는 훈련 데이터의 품질과 직접적인 관련이 있습니다. 올바른 훈련 데이터 파일을 사용하면 OCR 프로세스가 가능한 한 정확하게 수행됩니다.
- 호환성: 프로젝트에
{languageCode}.traineddata파일을 포함하면 다른 시스템이나 팀원의 기계 간에 OCR 환경을 복제하기 쉬워집니다.
{languageCode}.traineddata 버전 관리
다음과 같은 이유로 {languageCode}.traineddata를 버전 관리 시스템에 포함하는 것이 권장됩니다:
- 일관성: 모든 팀원이나 배포 환경이 동일한 버전의 훈련 데이터를 사용하도록 보장하여 다양한 환경에서 일관된 OCR 결과를 얻을 수 있습니다.
- 재현성: 이 파일을 버전 관리에 저장하면 나중에 또는 다른 기계에서 OCR 프로세스를 실행할 때 결과를 더 쉽게 재현할 수 있습니다.
- 의존성 관리: 버전 관리 시스템에 포함하면 의존성 관리에 도움이 되며 설정이나 환경 구성에 프로젝트가 올바르게 실행되는 데 필요한 파일이 포함되도록 보장합니다.
테스트를 실행하지 않고도 내 화면에서 어떤 텍스트가 발견되는지 쉽게 확인할 수 있는 방법이 있나요?
네, 이를 위해 CLI 마법사를 사용할 수 있습니다. 관련 문서는 여기에서 찾을 수 있습니다.
