Часто задаваемые вопросы
Мои тесты выполняются очень медленно
Когда вы используете @wdio/ocr-service, вы делаете это не для ускорения тестов, а потому что вам сложно находить элементы в вашем веб/мобильном приложении, и вы хотите более простой способ их поиска. И мы все, надеюсь, знаем, что когда вы что-то хотите получить, вы что-то теряете. Но..., существует способ заставить @wdio/ocr-service работать быстрее, чем обычно. Более подробную информацию об этом можно найти здесь.
Могу ли я использовать команды из этого сервиса с стандартными командами/селекторами WebdriverIO?
Да, вы можете комбинировать команды, чтобы сделать ваш скрипт еще более мощным! Рекомендуется использовать стандартные команды/селекторы WebdriverIO как можно чаще и использовать этот сервис только тогда, когда вы не можете найти уникальный селектор или ваш селектор станет слишком хрупким.
Почему не найден мой текст?
Прежде всего, важно понять, как работает процесс OCR в этом модуле, поэтому, пожалуйста, прочитайте эту страницу. Если вы все еще не можете найти свой текст, вы можете попробовать следующее.
Область изображения слишком большая
Когда модуль должен обработать большую область скриншота, он может не найти текст. Вы можете предоставить меньшую область, указав haystack при использовании команды. Пожалуйста, проверьте команды, какие из них поддерживают предоставление haystack.
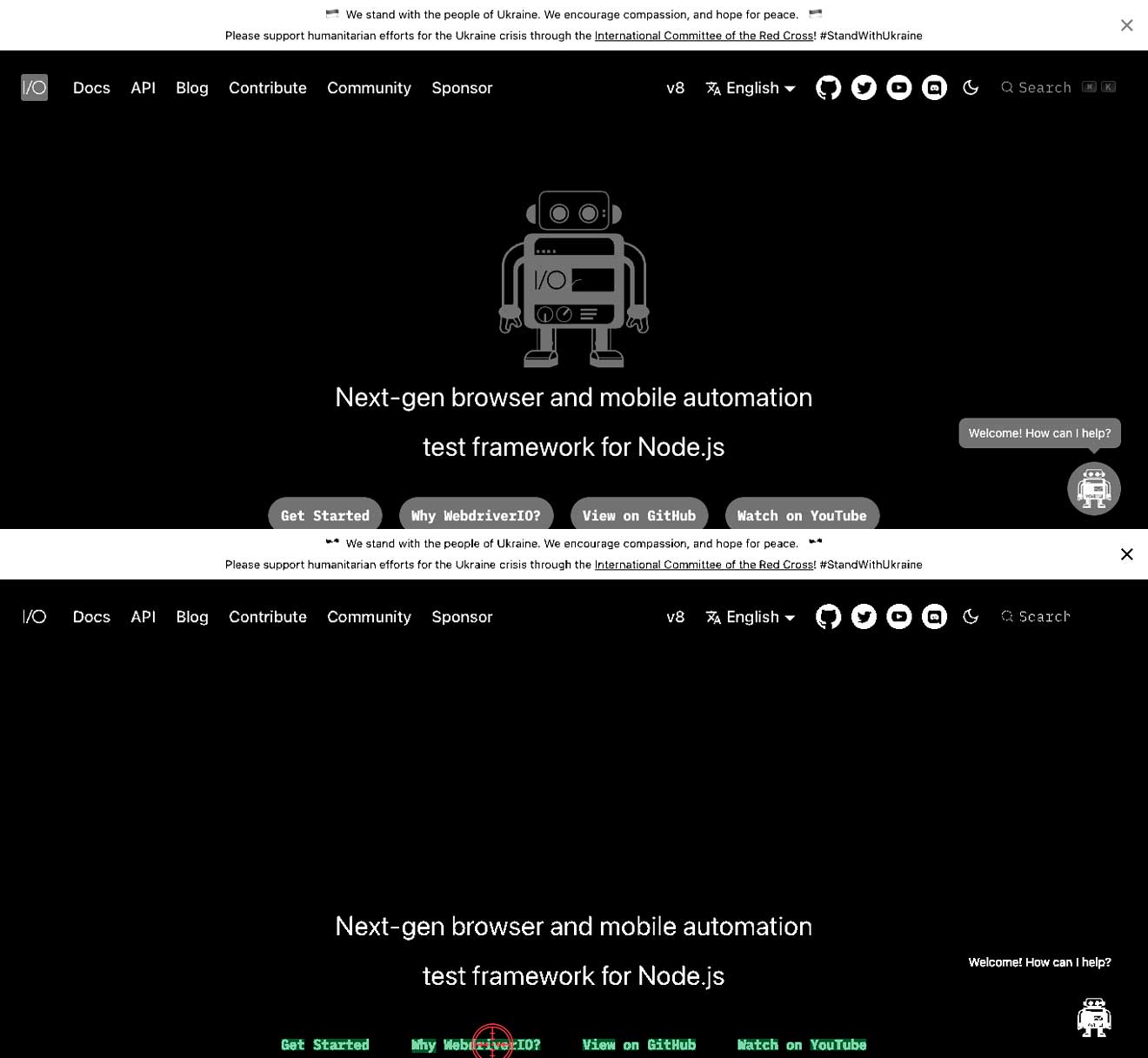
Контраст между текстом и фоном неправильный
Это означает, что у вас может быть светлый текст на белом фоне или темный текст на темном фоне. Это может привести к тому, что текст не будет найден. В примерах ниже вы можете видеть, что текст Why WebdriverIO? является белым и окружен серой кнопкой. В этом случае текст Why WebdriverIO? не будет найден. Увеличив контраст для конкретной команды, текст будет найден и на него можно будет кликнуть, см. второе изображение.
await driver.ocrClickOnText({
haystack: { height: 44, width: 1108, x: 129, y: 590 },
text: "WebdriverIO?",
// // С контрастом по умолчанию 0.25 текст не находится
contrast: 1,
});
Почему элемент кликается, но клавиатура на моих мобильных устройствах не появляется?
Это может происходить в некоторых текстовых полях, где клик определяется как слишком длинный и рассматривается как долгое нажатие. Вы можете использовать опцию clickDuration для ocrClickOnText и ocrSetValue, чтобы решить эту проблему. См. здесь.
Может ли этот модуль вернуть несколько элементов, как обычно делает WebdriverIO?
Нет, в настоящее время это невозможно. Если модуль находит несколько элементов, соответствующих предоставленному селектору, он автоматически найдет элемент с наивысшим показателем соответствия.
Могу ли я полностью автоматизировать свое приложение с помощью OCR-команд, предоставляемых этим сервисом?
Я никогда этого не делал, но в теории это должно быть возможно. Пожалуйста, сообщите нам, если вам это удастся ☺️.
Я вижу дополнительный файл с названием {languageCode}.traineddata, что это?
{languageCode}.traineddata - это файл с языковыми данными, используемый Tesseract. Он содержит обучающие данные для выбранного языка, которые включают необходимую информацию для эффективного распознавания Tesseract английских символов и слов.
Содержимое {languageCode}.traineddata
Файл обычно содержит:
- Данные о наборе символов: Информация о символах в английском языке.
- Языковая модель: Статистическая модель того, как символы образуют слова, а слова образуют предложения.
- Экстракторы признаков: Данные о том, как извлекать признаки из изображений для распознавания символов.
- Обучающие данные: Данные, полученные в результате обучения Tesseract на большом наборе изображений английского текста.
Почему важен {languageCode}.traineddata?
- Распознавание языка: Tesseract полагается на эти обученные файлы данных для точного распознавания и обработки текста на определенном языке. Без
{languageCode}.traineddataTesseract не сможет распознавать английский текст. - Производительность: Качество и точность OCR напрямую связаны с качеством обучающих данных. Использование правильного файла обученных данных обеспечивает максимальную точность процесса OCR.
- Совместимость: Включение файла
{languageCode}.traineddataв ваш проект облегчает воспроизведение среды OCR на разных системах �или машинах членов команды.
Версионирование {languageCode}.traineddata
Включение {languageCode}.traineddata в вашу систему контроля версий рекомендуется по следующим причинам:
- Согласованность: Это гарантирует, что все члены команды или среды развертывания используют точно такую же версию обучающих данных, что приводит к согласованным результатам OCR в разных средах.
- Воспроизводимость: Хранение этого файла в системе контроля версий облегчает воспроизведение результатов при запуске процесса OCR в более позднее время или на другой машине.
- Управление зависимостями: Включение его в систему контроля версий помогает в управлении зависимостями и гарантирует, что любая настройка или конфигурация среды включает необходимые файлы для правильной работы проекта.
Есть ли простой способ увидеть, какой текст найден на моем экране, без запуска теста?
Да, вы можете использовать наш CLI-мастер для этого. Документацию можно найти здесь
