Vanliga frågor
Mina tester är väldigt långsamma
När du använder denna @wdio/ocr-service så använder du den inte för att påskynda dina tester, du använder den eftersom du har svårt att lokalisera element i din webb/mobil-app och du vill ha ett enklare sätt att lokalisera dem. Och vi vet förhoppningsvis alla att när du vill ha något, så förlorar du något annat. Men...., det finns ett sätt att få @wdio/ocr-service att köra snabbare än normalt. Mer information om det kan hittas här.
Kan jag använda kommandona från denna tjänst med WebdriverIOs standardkommandon/selektorer?
Ja, du kan kombinera kommandona för att göra ditt skript ännu kraftfullare! Rådet är att använda WebdriverIOs standardkommandon/selektorer så mycket som möjligt och endast använda denna tjänst när du inte kan hitta en unik selektor, eller när din selektor skulle bli för skör.
Min text hittas inte, hur är det möjligt?
Först är det viktigt att förstå hur OCR-processen i denna modul fungerar, så läs gärna denna sida. Om du fortfarande inte kan hitta din text kan du prova följande saker.
Bildområdet är för stort
När modulen behöver bearbeta ett stort område av skärmbilden kanske den inte hittar texten. Du kan tillhandahålla ett mindre område genom att ange en 'haystack' när du använder ett kommando. Kontrollera kommandona vilka kommandon som stöder att tillhandahålla en haystack.
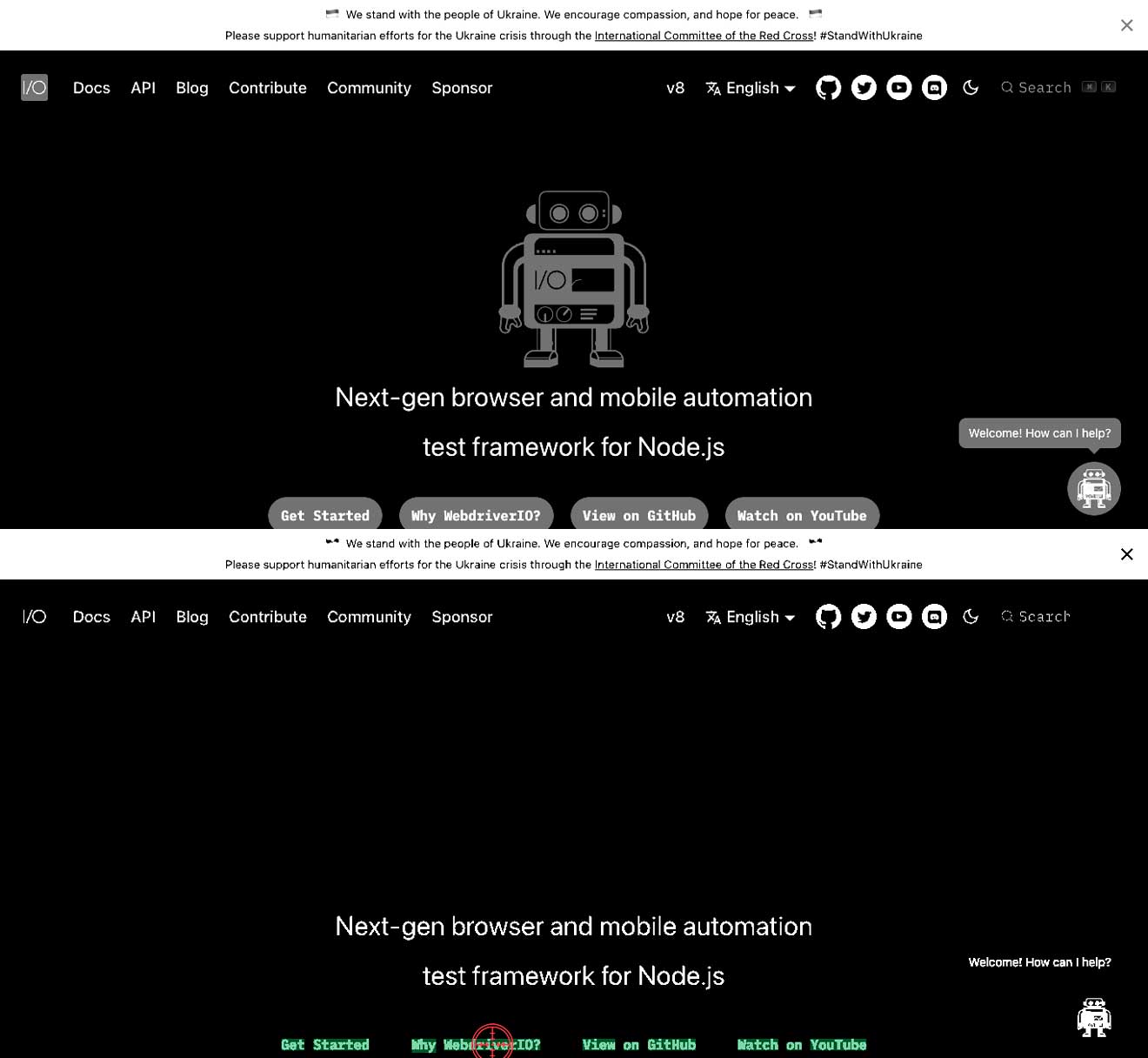
Kontrasten mellan texten och bakgrunden är inte korrekt
Detta innebär att du kan ha ljus text på en vit bakgrund eller mörk text på en mörk bakgrund. Detta kan resultera i att text inte kan hittas. I exemplen nedan kan du se att texten Why WebdriverIO? är vit och omgiven av en grå knapp. I detta fall kommer det att resultera i att texten Why WebdriverIO? inte hittas. Genom att öka kontrasten för det specifika kommandot hittar den texten och kan klicka på den, se den andra bilden.
await driver.ocrClickOnText({
haystack: { height: 44, width: 1108, x: 129, y: 590 },
text: "WebdriverIO?",
// // Med standardkontrasten på 0,25 hittas inte texten
contrast: 1,
});
Varför klickas mitt element men tangentbordet på mina mobila enheter kommer aldrig upp?
Detta kan hända på vissa textfält där klicket uppfattas som för långt och betraktas som ett långt tryck. Du kan använda alternativet clickDuration på ocrClickOnText och ocrSetValue för att lindra detta. Se här.
Kan denna modul returnera flera element som WebdriverIO normalt kan göra?
Nej, detta är för närvarande inte möjligt. Om modulen hittar flera element som matchar den angivna selektorn kommer den automatiskt att hitta det element som har högst matchningspoäng.
Kan jag helt automatisera min app med OCR-kommandona som tillhandahålls av denna tjänst?
Jag har aldrig gjort det, men teoretiskt sett borde det vara möjligt. Låt oss veta om du lyckas med det ☺️.
Jag ser en extra fil som heter {languageCode}.traineddata som har lagts till, vad är detta?
{languageCode}.traineddata är en språkdatafil som används av Tesseract. Den innehåller träningsdata för det valda språket, vilket inkluderar nödvändig information för att Tesseract effektivt ska kunna känna igen engelska tecken och ord.
Innehåll i {languageCode}.traineddata
Filen innehåller generellt:
- Teckenuppsättningsdata: Information om tecknen i det engelska språket.
- Språkmodell: En statistisk modell av hur tecken bildar ord och ord bildar meningar.
- Funktionsextraktörer: Data om hur man extraherar funktioner från bilder för igenkänning av tecken.
- Träningsdata: Data som härletts från träning av Tesseract på en stor uppsättning engelska textbilder.
Varför är {languageCode}.traineddata viktig?
- Språkigenkänning: Tesseract förlitar sig på dessa tränade datafiler för att korrekt känna igen och bearbeta text på ett specifikt språk. Utan
{languageCode}.traineddataskulle Tesseract inte kunna känna igen engelsk text. - Prestanda: Kvaliteten och noggrannheten hos OCR är direkt relaterad till kvaliteten på träningsdata. Att använda rätt tränad datafil säkerställer att OCR-processen är så exakt som möjligt.
- Kompatibilitet: Att säkerställa att filen
{languageCode}.traineddataingår i ditt projekt gör det lättare att replikera OCR-miljön över olika system eller teammedlemmars maskiner.
Versionshantering av {languageCode}.traineddata
Att inkludera {languageCode}.traineddata i ditt versionskontrollsystem rekommenderas av följande skäl:
- Konsekvens: Det säkerställer att alla teammedlemmar eller driftmiljöer använder exakt samma version av träningsdata, vilket leder till konsekventa OCR-resultat i olika miljöer.
- Reproducerbarhet: Att lagra denna fil i versionskontroll gör det lättare att reproducera resultat när OCR-processen körs vid ett senare tillfälle eller på en annan maskin.
- Beroendehantering: Att inkludera den i versionskontrollsystemet hjälper till att hantera beroenden och säkerställer att alla setup- eller miljökonfigurationer inkluderar de nödvändiga filerna för att projektet ska fungera korrekt.
Finns det ett enkelt sätt att se vilken text som hittas på min skärm utan att köra ett test?
Ja, du kan använda vår CLI-guide för det. Dokumentation kan hittas här
