常见问题
我的测试非常慢
当你使用@wdio/ocr-service时,你并不是为了加速测试而使用它,你使用它是因为你在Web/移动应用中定位元素时遇到困难,想要一种更简单的方法来定位它们。我们都希望知道当你想要得到某些东西时,你会失去其他东西。但是....,有一种方法可以使@wdio/ocr-service比正常情况下执行得更快。更多相关信息可以在这里找到。
我可以将此服务中的命令与默认的WebdriverIO命令/选择器结合使用吗?
是的,你可以组合这些命令使你的脚本更加强大!建议是尽可能多地使用默认的WebdriverIO命令/选择器,只有在找不到唯一的选择器或者你的选择器变得过于脆弱时才使用此服务。
我的文本没有被找到,这是怎么回事?
首先,了解这个模块中OCR过程的工作原理很重要,所以请阅读这个页面。如果你仍然找不到你的文本,你可以尝试以下几点。
图像区域太大
当模块需要处理屏幕截图的大面积区域时,它可能找不到文本。你可以通过在使用命令时提供一个范围区域(haystack)来指定一个较小的区域。请查看命令哪些命令支持提供范围区域。
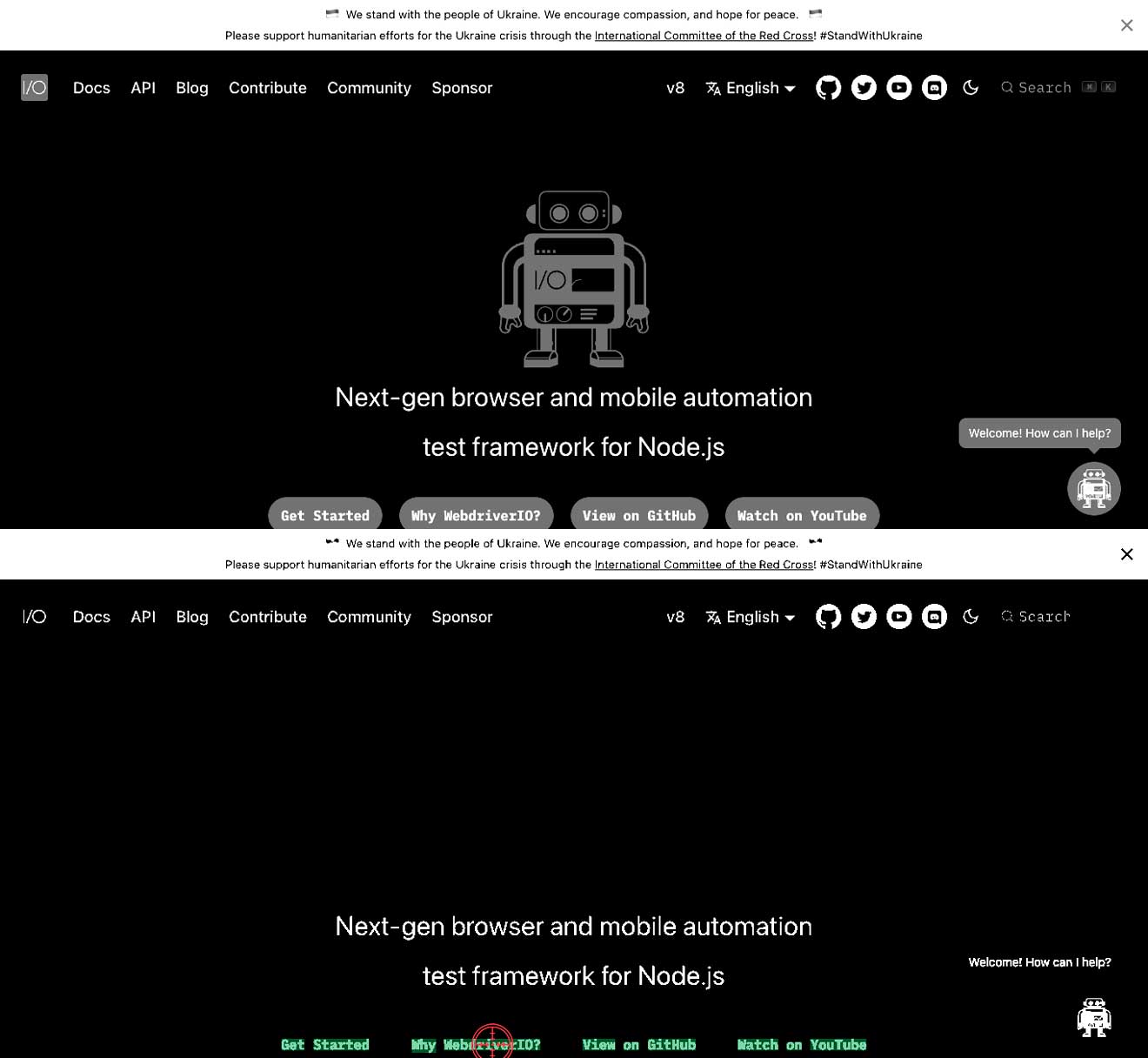
文本与背景之间的对比度不正确
这意味着你可能在白色背景上有浅色文本或在深色背景上有深色文本。这可能导致无法找到文本。在下面的例子中,你可以看到文本Why WebdriverIO?是白色的,并被灰色按钮包围。在这种情况下,将导致找不到Why WebdriverIO?文本。通过增加特定命令的对比度,它找到了文本并可以点击它,见第二张图片。
await driver.ocrClickOnText({
haystack: { height: 44, width: 1108, x: 129, y: 590 },
text: "WebdriverIO?",
// // 使用默认对比度0.25时,文本无法找到
contrast: 1,
});
为什么我的元素被点击了,但移动设备上的键盘从不弹出?
这种情况可能发生在某些文本字段上,其中点击被认为太长并被视为长按。你可以在ocrClickOnText和ocrSetValue上使用clickDuration选项来缓解这个问题。参见这里。
这个模块能否像WebdriverIO通常那样返回多个元素?
不,这目前是不可能的。如果模块找到多个与提供的选择器匹配的元素,它将自动找到具有最高匹配分数的元素。
我可以完全使用此服务提供的OCR命令自动化我的应用程序吗?
我从未做过,但理论上应该是可能的。如果你成功了,请告诉我们☺️。
我看到添加了一个名为{languageCode}.traineddata的额外文件,这是什么?
{languageCode}.traineddata是Tesseract使用的语言数据文件。它包含所选语言的训练数据,其中包括Tesseract有效识别英文字符和单词所需的必要信息。
{languageCode}.traineddata的内容
该文件通常包含:
- 字符集数据: 有关英语语言中字符的信息。
- 语言模型: 关于字符如何形成单词以及单词如何形成句子的统计模型。
- 特征提取器: 关于如何从图像中提取用于识别字符的特征的数据。
- 训练数据: 从大量英文文本图像训练Tesseract得到的数据。
为什么{languageCode}.traineddata很重要?
- 语言识别: Tesseract依靠这些训练数据文件准确识别和处理特定语言的文本。没有
{languageCode}.traineddata,Tesseract将无法识别英文文本。 - 性能: OCR的质量和准确性与训练数据的质量直接相关。使用正确的训练数据文件确保OCR过程尽可能准确。
- 兼容性: 确保将
{languageCode}.traineddata文件包含在你的项目中,使得更容易在不同系统或团队成员的机器上复制OCR环境。
版本控制{languageCode}.traineddata
建议将{languageCode}.traineddata包含在你的版本控制系统中,原因如下:
- 一致性: 它确保所有团队成员或部署环境使用完全相同版本的训练数据,从而在不同环境中产生一致的OCR结果。
- 可重现性: 将此文件存储在版本控制中,使得在以后或在不同机器上运行OCR过程时更容易重现结果。
- 依赖管理: 将其包含在版本控制系统中有助于管理依赖关系,并确保任何设置或环境配置都包含项目正确运行所需的必要文件。
有没有一种简单的方法可以查看我的屏幕上找到了哪些文本而不运行测试?
是的,你可以使用我们的CLI向导。文档可以在这里找到
