Często Zadawane Pytania
Moje testy są bardzo wolne
Kiedy korzystasz z @wdio/ocr-service, nie używasz go do przyspieszenia testów, ale dlatego, że masz trudności z lokalizacją elementów w aplikacji internetowej/mobilnej i chcesz łatwiejszego sposobu na ich zlokalizowanie. I wszyscy mamy nadzieję, że wiemy, że gdy czegoś chcesz, coś innego tracisz. Ale..., istnieje sposób, aby @wdio/ocr-service działał szybciej niż normalnie. Więcej informacji na ten temat można znaleźć tutaj.
Czy mogę używać poleceń z tej usługi z domyślnymi poleceniami/selektorami WebdriverIO?
Tak, możesz łączyć polecenia, aby uczynić swój skrypt jeszcze potężniejszym! Zaleca się używanie domyślnych poleceń/selektorów WebdriverIO tak często, jak to możliwe, i korzystanie z tej usługi tylko wtedy, gdy nie możesz znaleźć unikalnego selektora lub Twój selektor stanie się zbyt kruchy.
Mój tekst nie został znaleziony, jak to możliwe?
Po pierwsze, ważne jest zrozumienie, jak działa proces OCR w tym module, więc przeczytaj tę stronę. Jeśli nadal nie możesz znaleźć swojego tekstu, możesz spróbować następujących rzeczy.
Obszar obrazu jest zbyt duży
Gdy moduł musi przetworzyć duży obszar zrzutu ekranu, może nie znaleźć tekstu. Możesz zapewnić mniejszy obszar, dostarczając stos (haystack) podczas używania polecenia. Sprawdź polecenia, które obsługują dostarczanie stosu.
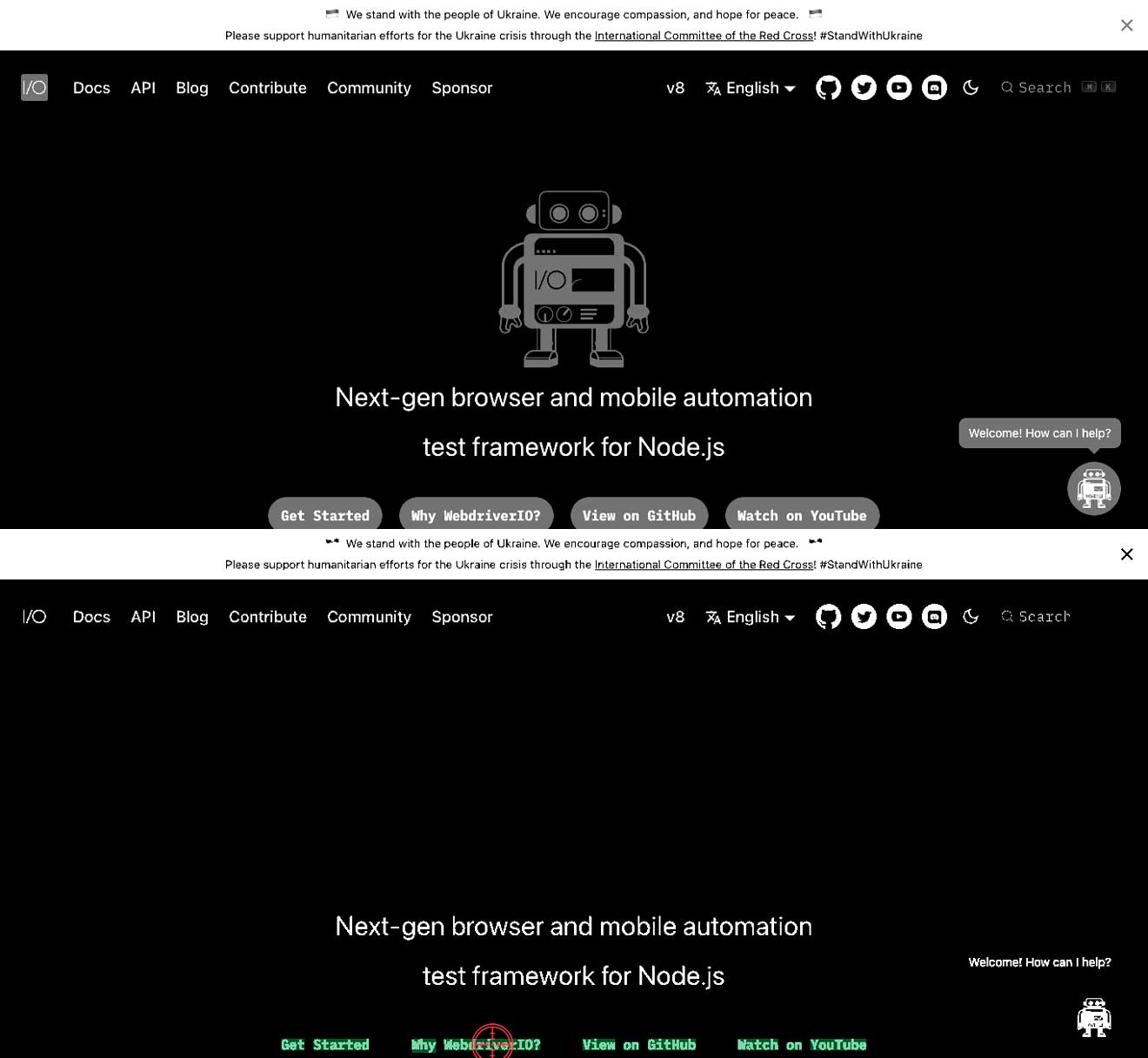
Kontrast między tekstem a tłem nie jest prawidłowy
Oznacza to, że możesz mieć jasny tekst na białym tle lub ciemny tekst na ciemnym tle. To może skutkować niemożnością znalezienia tekstu. W poniższych przykładach widzisz, że tekst Why WebdriverIO? jest biały i otoczony szarym przyciskiem. W tym przypadku spowoduje to nieznalezienie tekstu Why WebdriverIO?. Zwiększając kontrast dla konkretnego polecenia, znajdzie tekst i będzie mógł na niego kliknąć, zobacz drugi obraz.
await driver.ocrClickOnText({
haystack: { height: 44, width: 1108, x: 129, y: 590 },
text: "WebdriverIO?",
// // Z domyślnym kontrastem 0,25 tekst nie jest znajdowany
contrast: 1,
});
Dlaczego mój element zostaje kliknięty, ale klawiatura na moich urządzeniach mobilnych nigdy się nie pojawia?
Może to wystąpić w niektórych polach tekstowych, gdzie kliknięcie jest określane jako zbyt długie i uznawane za długie dotknięcie. Możesz użyć opcji clickDuration w ocrClickOnText i ocrSetValue, aby temu zaradzić. Zobacz tutaj.
Czy ten moduł może zwrócić wiele elementów jak normalnie może to zrobić WebdriverIO?
Nie, obecnie nie jest to możliwe. Jeśli moduł znajdzie wiele elementów pasujących do podanego selektora, automatycznie znajdzie element, który ma najwyższy wynik dopasowania.
Czy mogę w pełni zautomatyzować moją aplikację za pomocą poleceń OCR dostarczanych przez tę usługę?
Nigdy tego nie robiłem, ale teoretycznie powinno być to możliwe. Daj nam znać, jeśli ci się to uda ☺️.
Widzę dodatkowy plik o nazwie {languageCode}.traineddata, co to jest?
{languageCode}.traineddata to plik danych językowych używany przez Tesseract. Zawiera dane treningowe dla wybranego języka, które obejmują niezbędne informacje dla Tesseract do skutecznego rozpoznawania angielskich znaków i słów.
Zawartość {languageCode}.traineddata
Plik zwykle zawiera:
- Dane zestawu znaków: Informacje o znakach w języku angielskim.
- Model językowy: Statystyczny model tego, jak znaki tworzą słowa, a słowa tworzą zdania.
- Ekstraktory cech: Dane o tym, jak wyodrębnić cechy z obrazów do rozpoznawania znaków.
- Dane treningowe: Dane pochodzące z treningu Tesseract na dużym zbiorze obrazów tekstu angielskiego.
Dlaczego {languageCode}.traineddata jest ważny?
- Rozpoznawanie języka: Tesseract polega na tych przeszkolonych plikach danych, aby dokładnie rozpoznawać i przetwarzać tekst w określonym języku. Bez
{languageCode}.traineddata, Tesseract nie byłby w stanie rozpoznać tekstu angielskiego. - Wydajność: Jakość i dokładność OCR są bezpośrednio związane z jakością danych treningowych. Używanie poprawnego pliku danych treningowych zapewnia, że proces OCR jest tak dokładny, jak to możliwe.
- Kompatybilność: Upewnienie się, że plik
{languageCode}.traineddatajest zawarty w Twoim projekcie, ułatwia replikację środowiska OCR na różnych systemach lub maszynach członków zespołu.
Wersjonowanie {languageCode}.traineddata
Włączenie {languageCode}.traineddata do systemu kontroli wersji jest zalecane z następujących powodów:
- Spójność: Zapewnia, że wszyscy członkowie zespołu lub środowiska wdrożeniowe używają dokładnie tej samej wersji danych treningowych, co prowadzi do spójnych wyników OCR w różnych środowiskach.
- Odtwarzalność: Przechowywanie tego pliku w kontroli wersji ułatwia odtworzenie wyników podczas uruchamiania procesu OCR w późniejszym terminie lub na innej maszynie.
- Zarządzanie zależnościami: Włączenie go do systemu kontroli wersji pomaga w zarządzaniu zależnościami i zapewnia, że każda konfiguracja lub konfiguracja środowiska zawiera niezbędne pliki do poprawnego działania projektu.
Czy istnieje łatwy sposób, aby zobaczyć, który tekst jest znajdowany na moim ekranie bez uruchamiania testu?
Tak, możesz użyć naszego kreatora CLI. Dokumentację można znaleźć tutaj
